
Sytuacja podobna do tej opisanej w case study nr 10 wystąpiła na stronie kolegi. Ta jednak została zaindeksowana w wersji z HTTPS przez przypadek, co nastąpiło 12 grudnia. Kiedy dostałam informację o problemie, w pierwszej kolejności odpytałam o site i od razu miałam déjà vu — strona główna i najważniejsze podstrony spadły na odległe pozycje i były zaindeksowane w wersji z HTTPS zamiast HTTP.
Zerknęłam więc do monitora pozycji, widząc, że spadki dotyczyły większości fraz, co potwierdzało Search Console. Oto wykres zmian w pozycjach dla 4 wybranych fraz:
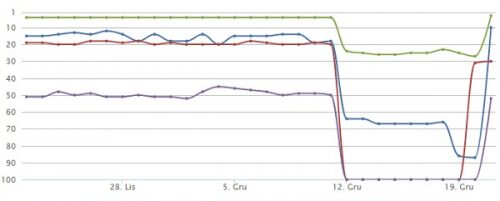
Od razu dostałam sygnał, że linkowanie może nie być do końca prawidłowe, jednak szybka analiza danych z Majestic i Search Console pokazała, że nie tylko linków nie ma zbyt wiele, ale także ich profil jest całkiem ciekawy, więc nie powinny one stanowić problemów. Na pierwszy rzut i tak poszły działania on-site, które w tym przypadku ograniczyły się do ustawienia 301 na wersję z HTTP i przyspieszenie zauważenia przekierowania dzięki formularzowi „Pobierz jako Google”.
Jak widać na powyższym wykresie, na efekt nie trzeba było długo czekać. Niewykluczone jednak, że jeszcze przez pewien okres na różnych DC będą widoczne inne wersje adresów, dlatego spadki mogą się powtarzać, chociaż tym razem zapewne na krótszy okres.
Wskazówka:
Oprócz tego, co napisałam we wskazówce do pierwszego przykładu, warto pobrać pełną listę zaindeksowanych podstron i przejrzeć ją dokładnie. Można w tym celu skorzystać z rozszerzenia do Chrome o nazwie Scraper. Wystarczy:
- ustawić w Google ilość podstron na 1 stronie wyników na 100;
- odpytać wyszukiwarkę o ilość zaindeksowanych podstron;
- kliknąć dowolny wynik prawym przyciskiem myszy i wybrać „Scrape Similar”;
W rezultacie uzyskujemy czytelną listę, z której nie tylko sprawdzimy zaindeksowane podstrony, ale także, sortując po tytułach, możemy szybko sprawdzić, czy nie mamy duplikatów.
Taka analiza pozwoli nam to upewnić się co do tego, czy nie występują jeszcze jakieś problemy z indeksacją i czy np. nie powinniśmy dopisać w pliku robots.txt blokady indeksacji niektórych adresów. Mogą to być wyniki wyszukiwania, sortowania, filtrowania czy też wersje artykułów do wydruku. Może się również okazać, że skrypt — mimo włączonego modułu przyjaznych adresów URL — wyświetla podstrony również pod swoimi oryginalnymi, dalekimi od przyjaznych adresami.
Treść została oryginalnie opublikowana we wpisie „[case study] DC powodem a’la filtra” [SeoStation.pl].